
Das maschinenlesbare Web: Wie Inhalte für KI-Systeme strukturiert werden
Unternehmen und Verlage passen ihre Inhalte systematisch an, damit KI-Systeme im Web Angaben korrekt extrahieren und zitieren. Anbieter wie AmICited.com und FlowHunt.io liefern inzwischen Werkzeuge zur Überwachung und Automatisierung der Strukturierung, während die Praxis zeigt, dass deutlich strukturierte Inhalte häufiger in KI-Überblicken erscheinen.
Warum maschinenlesbare Inhalte im Web für Verlage und Plattformen entscheidend sind
Die zentrale Ankündigung: Inhalte müssen nicht nur für Menschen lesbar, sondern explizit maschinenlesbar sein, damit LLMs und Such-Assistenten sie korrekt einordnen. Das betrifft sowohl die inhaltliche Semantik als auch das zugrundeliegende Datenformat.
Wie KI-Systeme Inhalte verarbeiten und warum Strukturierung zählt
Kernmechanismen wie Chunking, Einbettungen und Retrieval-Modelle zerlegen Seiten in verarbeitbare Blöcke. Saubere H‑Strukturen, kurze Absätze und explizite Metadaten verbessern die Genauigkeit der Datenverarbeitung.
Konkrete Auswirkungen für Medien, SEO und Marken
Praxisbeispiele zeigen schnelle Effekte: Ein großes Nachrichtenportal berichtete über deutlich mehr Sichtbarkeit in KI-Übersichten nach Umstrukturierung. Gut strukturierte Artikel werden seltener falsch zugeordnet und erhöhen die Chance auf korrekte Markennennung.
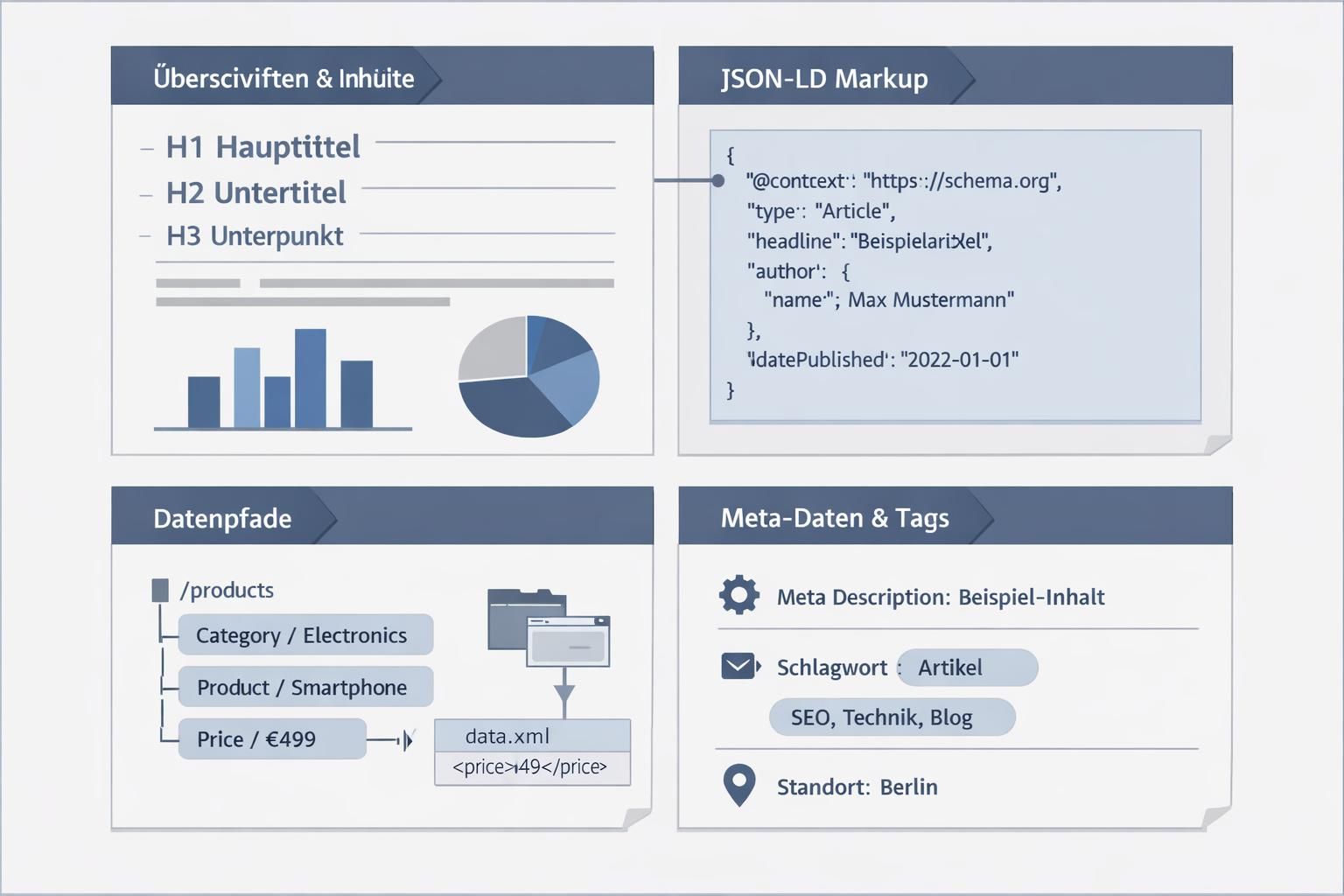
Kernprinzipien der Strukturierung maschinenlesbarer Inhalte für das Web
Redakteure müssen Inhalte so anlegen, dass jede H2‑Einheit genau eine konzeptionelle Aufgabe trägt. Klare Definitionen, kurze Absätze und vorhersehbare Abschnittsmuster bilden das Rückgrat maschinenlesbarer Inhalte.
Überschriften, Metadaten und standardisierte Datenformate
Die Hierarchie H1→H2→H3 dient als primärer Anker für Einbettungen. Ergänzt durch schema.org-Markup im JSON‑LD-Format liefern Metadaten explizite Kontextsignale, die KI-Systeme unmittelbar auslesen können.
Fehler und Best Practices in der Praxis
Typische Fehler sind inkonsistente Überschriften und lange Textblöcke. Beispiele aus Commerce- und FAQ‑Umstellungen belegen: strukturierte Seiten erzielten signifikant mehr KI-Zitate, wenn Listen, klare Kennzahlen und prägnante Themensätze genutzt wurden.
Automatisierung, Tools und Folgen für Datenverarbeitung im KI-Zeitalter
Skalierung gelingt nur mit Automatisierung: Tools generieren strukturiertes Markup, überwachen KI-Zitate und orchestrieren Inhaltsupdates. Diese Kombination verändert Redaktions- und Entwicklungsprozesse nachhaltig.
Plattformen zur Überwachung und automatischen Umsetzung
Anbieter wie AmICited.com verfolgen, wie Seiten in GPT-Antworten, Perplexity und Google‑KI-Überblicken erscheinen. FlowHunt.io automatisiert Markup-Generierung und Inhaltsumstrukturierung; SEO-Tools wie SEMrush oder Ahrefs ergänzen die Analyse für KI‑Überblicke.
Auswirkungen auf Workflows, Qualitätssicherung und Datenverarbeitung
Redaktionen müssen Publikationsprozesse umstellen: Autoren liefern definitorische Einstiege, Entwickler implementieren JSON‑LD und QA prüft Einbettungsqualität. Automatisierte Prüfungen reduzieren Fehler und beschleunigen Datenverarbeitung in Vektorindizes.
Insight: Wer seine Inhalte konsequent maschinenlesbar aufbaut — klare Semantik, validiertes Datenformat und Automatisierung — erhöht die Wahrscheinlichkeit, in KI-generierten Antworten sichtbar und korrekt zitiert zu werden. Dieser Wandel verlangt organisatorische Anpassungen, bietet aber erhebliche Chancen für Sichtbarkeit im modernen Web.






