
Wie Inhalte strukturiert werden müssen, um von KI-Systemen genutzt zu werden
KI-gesteuerte Suchsysteme und Chatbots wie ChatGPT, Gemini und Perplexity bewerten Webtexte anders als klassische Suchmaschinen. Entscheidend sind heute nicht mehr einzelne Keywords, sondern eine klare Inhaltsstruktur, nachvollziehbare Metadaten und maschinenlesbare Datenformatierung, die Maschinelles Lernen-Modelle zuverlässig verarbeiten können.
Wie KI Texte kontextuell erfasst und einordnet
Bei der Verarbeitung analysieren Large Language Models Texte via Semantische Analyse und Textklassifikation, sie zerlegen Inhalte in kurze, isolierbare Einheiten. Entscheidend sind Verständlichkeit, Quellennachweise und eine strukturierte Gliederung mit aussagekräftigen Überschriften.
Kriterien für Relevanz und Zitierfähigkeit
Suchsysteme priorisieren Inhalte, die thematisch fokussiert sind und einen klaren fachlichen Kontext liefern. Google verweist in seinen Richtlinien weiterhin auf die Notwendigkeit nutzerzentrierter Inhalte; das entspricht dem E‑E‑A‑T‑Ansatz, der E‑E‑A‑T (Expertise, Experience, Authoritativeness, Trustworthiness) sichtbar verlangt.
Praktisch bedeutet das: Seiten, die eindeutige Themenblöcke, interne Verlinkungen und belegbare Quellen bieten, werden von Modellen besser erfasst. MDN-Verweise zur HTML-Struktur zeigen, wie saubere Inhaltsstruktur und semantische Tags die automatische Erkennung erleichtern.
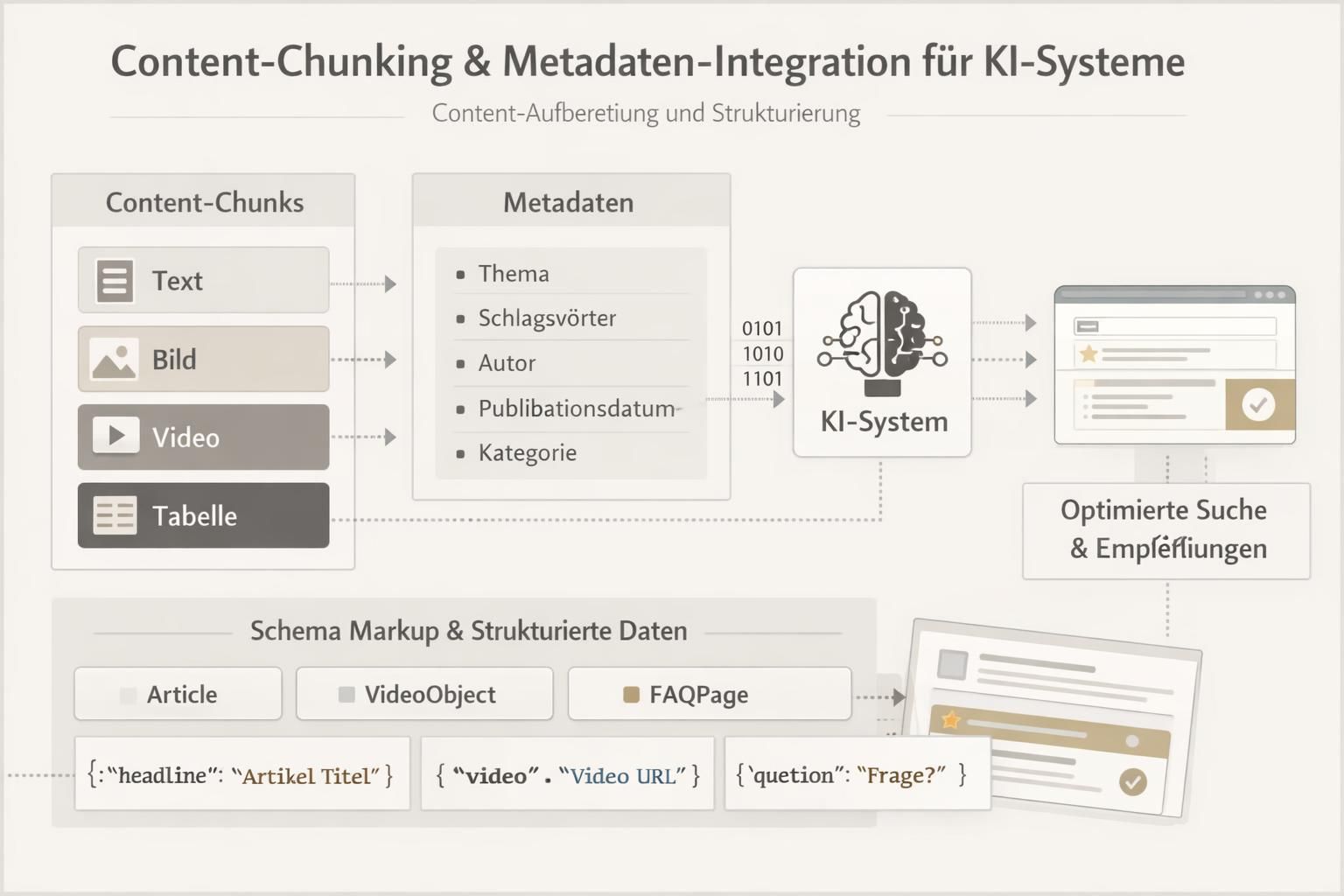
Praktische Maßnahmen für Redaktion und technische Umsetzung
Redaktionen sollten Texte in kompakte, zitierfähige Abschnitte gliedern und sichtbare Metadaten ergänzen. Strukturierte Daten wie Article oder FAQ-Schema erhöhen die Chance, dass Inhalte in AI‑Overviews auftauchen.
Technische Prinzipien und redaktionelle Regeln
Wesentliche Maßnahmen umfassen eine klare H‑Überschriftenhierarchie, kurze Absätze und gezielte Datenformatierung. Für Such- und KI-Systeme ist zudem relevant, welche Rolle Datenanreicherung und Datenintegration spielen: interne Links, Zitationspfade und strukturierte Metafelder geben Kontext für die automatische Verarbeitung.
Mobile‑First-Performance, saubere Markups und Vermeidung von Duplicate Content sind technisches Fundament. Sichtbare Autor:innenangaben und Veröffentlichungsdaten stärken die Glaubwürdigkeit gegenüber Algorithmen und Leser:innen.
Auswirkungen auf Sichtbarkeit und redaktionelle Prioritäten
Nicht alle Inhalte haben die gleiche Chance, von KI-Systemen zitiert zu werden. Answer-Content wie FAQs, How‑tos und definitorische Beiträge ist besonders geeignet, weil er klare, isolierbare Antworten liefert.
Welche Inhalte bevorzugt werden und warum
Modelle erstellen Antworten aus kleinen Informationsblöcken; deshalb sind kompakte, präzise Sätze mit belegbaren Fakten erfolgversprechender als lange, generische Texte. Die Automatisierte Verarbeitung bevorzugt zudem Inhalte, die mittels Ontologien und klarer thematischer Verknüpfungen eingeordnet werden können.
Für Verlage und Brands heißt das: Priorisieren Sie Inhalte mit hohem Antwortwert und investieren Sie in Datenanreicherung und semantische Struktur. So steigt die Wahrscheinlichkeit, in Zusammenfassungen von ChatGPT oder Google AI Overviews genannt zu werden.
Klare Inhaltsstruktur, durchdachte Metadaten und saubere Datenformatierung sind heute die Voraussetzung, damit Inhalte von KI-Systemen verstanden, zitiert und weiterverwendet werden. Redaktionen, die diese technischen und redaktionellen Regeln kombinieren, verbessern ihre Sichtbarkeit in einer Suchlandschaft, die zunehmend von Maschinelles Lernen und Semantische Analyse gesteuert wird.






